



Normalizer
transformation is an Active and Connected transformation.
The Normalizer
transformation receives a row that contains multiple-occurring columns and
returns a row for each instance of the multiple-occurring data. The
transformation processes multiple-occurring columns or multiple-occurring
groups of columns in each source row.
The Normalizer
transformation parses multiple-occurring columns from COBOL sources, relational
tables, or other sources. It can process multiple record types from a COBOL
source that contains a REDEFINES clause.
For example, you might
have a relational table that stores four quarters of sales by store. You need
to create a row for each sales occurrence. You can configure a Normalizer
transformation to return a separate row for each quarter.
You can create a VSAM
Normalizer transformation or a pipeline Normalizer transformation:
- VSAM Normalizer transformation. A non-reusable transformation that is a Source
Qualifier transformation for a COBOL source. The Mapping Designer creates
VSAM Normalizer columns from a COBOL source in a mapping. The column
attributes are read-only. The VSAM Normalizer receives a
multiple-occurring source column through one input port.
- Pipeline Normalizer transformation. A transformation that processes multiple-occurring data
from relational tables or flat files. You create the columns manually and
edit them in the Transformation Developer or Mapping Designer. The
pipeline Normalizer transformation represents multiple-occurring columns
with one input port for each source column occurrence.
Source Data:
EmpId
|
Ename
|
Salary1
|
Salary2
|
Salary3
|
1001
|
Raju
|
5000
|
8000
|
10000
|
1002
|
Ravi
|
6000
|
7000
|
11000
|
1003
|
Anil
|
4000
|
3000
|
5000
|
Target Data:
EmpId
|
Ename
|
Salary
|
1001
|
Raju
|
5000
|
1001
|
Raju
|
8000
|
1001
|
Raju
|
10000
|
1002
|
Ravi
|
6000
|
1002
|
Ravi
|
7000
|
1002
|
Ravi
|
11000
|
1003
|
Anil
|
4000
|
1003
|
Anil
|
3000
|
1003
|
Anil
|
5000
|
Sample mapping:
1. Connect and Open the
folder if not already opened.
2. Select Tools -->
Mapping Designer

3. Select Mappings
--> Create
It will pop-up
"Mapping Name". Enter the mapping name of your choice" and Click
on 'OK'. Example: m_emp_salaries

4. Drag the Source and
Target definitions into workspace if they are already exist. If not click hereto know how to create or import Table definitions.

5. Select
'Transformation' from Menu --> Create

a) That will appear you
'Select the transformation type to create:'

b) Select 'Normalizer'
from drop down and 'Enter a new name for this transformation:' as
"nrm_salaries"
c) Click 'Create' and
'Done'
or
a) Click on Normalizer
Transformation icon marked below in below snapshot.

b) Click in the workspace in Mapping Designer.
c) Select NRMTRANS in
workspace and Right Click --> Edit.

d) In Transformation tab
--> Click on 'Rename' highlighted above which will pop-up 'Rename
Transformation'. Enter the Transformation Name: "nrm_salaries"
e) Click on 'OK'
f) Click on 'Apply' and
'OK'.
Note: We cannot drag any
port into Normalizer transformation. We have to create port and defined
datatypes, length.
6. Select 'nrm_salaries'
Normalizer transformation in workspace and Right Click --> Edit.
a) Go to 'Normalizer'
tab, to create ports

b) Now, defined the
'SALARY' occurrence as 3. Which tells Informatica who many sequence columns need
to loop for the other columns.

c) Now, go to the tab
Port and see, we got 3 ports for salary.

d) Go to the Properties
tab

Reset: At the end of a session, resets the value
sequence for each generated key value to the value it was before the session
Restart: Starts the generated key sequence at 1.
Each time you run a session, the key sequence value starts at 1 and overrides
the sequence value on the Ports tab.
e) Click 'Apply' and
Click 'OK.

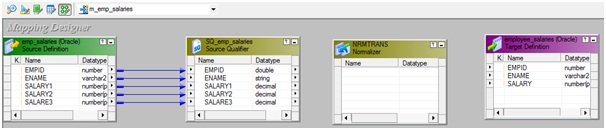
7. Drag required ports
from 'SQ_emp_salaries' Source Qualifier to 'nrm_salaries' Normalizer
Transformation then 'employee_salaries' target.

8. Select 'Mapping' from
Menu --> Validate.
9. Select 'Repository'
from Menu --> Save

Post an example for mainframe dataset read
ReplyDeleteThanks a lot!!!
ReplyDeletewah bhai ..!! maan gaye :)
ReplyDeleteGreat work, by far the best explanation on normalizer that i found
ReplyDeleteNice explanation...Can you help me with a scenario like above only but not sure how many quarter occurrences are there in the source. Or it is dynamic and keep changing for every records in source.
ReplyDeleteLIke Emp-1 is in company for 3 year so he will be havivng 12 Qtr sales details.
While emp-2 is there only for 1 year so only 4 qtr sales details are there for him.
Can we use Normilzer to create 12 records for EMP-1 and 4 records for Emp-2 in output.
Nice explanation of all concepts not only single topic, you covered all basic complete implementation so it will very helpful for complex code implement.Thanks Gowtham Great job.
ReplyDeleteAwesome explanation. Thanks Alot.
ReplyDeleteExcellent. Great work!
ReplyDeleteNice webpage...i think you have updated today.
ReplyDeleteThanks,
Vijay
Nice look ..updated blog...
ReplyDeleteGreat Work Gowtham! Keep it up! and many thanks!
ReplyDeleteExcellent Blog !!!!!
ReplyDeleteWhats the use of the last two columns GK_ and GCID_?
ReplyDeleteThe Integration Service increments the generated key (GK) sequence number each time it processes a source row and The transformation returns a generated column ID (GCID) for each instance of a multiple-occurring field.
ReplyDeleteexample:
Emp_Name Jan_Sal Feb_Sal Mar_Sal
Raju 5000 7000 10000
Kamle 7000 9000 8000
Output:
Emp_Name Sal GK_ID GCID
Raju 5000 1 1
Raju 7000 1 2
Raju 10000 1 3
Kamle 7000 2 1
Kamle 9000 2 2
Kamle 8000 2 3
Please let drop a mail if you still any confusion.
Thanks,
Gowtham
Good... Thanks
DeleteThis is very good information
ReplyDeleteinformatica online training, informatica training in bangalore, informaitca training
Gotham Bhai superb explanation... really bro it's cut to cut clarified
ReplyDeleteGotham Bhai superb explanation... really bro it's cut to cut clarified
ReplyDeleteHi,
ReplyDeleteI must appreciate you for providing such a valuable content for us. This is one amazing piece of article. Helped a lot in increasing my knowledge on Normalizer transformation. Thanks for sharing this article.
Regards,
Catchexperts, best Informatica training institute in Hyderabad, India
Thank you for providing useful content Informatica Online Training
ReplyDelete